You are hereVirtuosoNext
VirtuosoNext
The legacy of Tony Hoare's CSP and Altreonic
 Professor emeritus Hoare has passed away at the age of 92. Known to many as C. A. R. Hoare, or Tony Hoare, he was one of the great minds in the domain of software engineering. He received the ACM Turing Award in 1980. Altreonic's history that has it roots in the late 1980's, was essentially based on Hoare's CSP process algebra. CSP stands for Communicating Sequential Processes. Here's my personal road that followed. Note that I am an engineer, not an academic. An engineering approach is to make something that works in practice but following sound principles that academics have developed.
Professor emeritus Hoare has passed away at the age of 92. Known to many as C. A. R. Hoare, or Tony Hoare, he was one of the great minds in the domain of software engineering. He received the ACM Turing Award in 1980. Altreonic's history that has it roots in the late 1980's, was essentially based on Hoare's CSP process algebra. CSP stands for Communicating Sequential Processes. Here's my personal road that followed. Note that I am an engineer, not an academic. An engineering approach is to make something that works in practice but following sound principles that academics have developed.
My initial exposure to software was while studying as an engineer in the domain of electronics and applied mechanics. We had an old IBM-360 and we learned to program in Algol-68 and Fortran. Later, as PCs became affordable, Pascal was added. Meanwhile, Tony Hoare had developed CSP, which later on was adopted as the conceptual framework for a unique processor, called the Transputer (ex-INMOS). At the time it was very different from the mainstream Intel processors. The transputer was a RISC-like CPU with unique support for software and hardware concurrency. It natively supported small processes and inter-processor communication. As it had a small register set and hence context process switching was fast and interprocessor communication had a low latency. For programming the unique occam language was developed. Occam was a direct implementation of a subset of CSP with processes and communication channels.
Just before that time, I had envisioned the concept of a parallel computer (using optical communication). With hindsight, building a parallel computer is easy. What's hard is how to program it in an efficient and scalable way. At that time the focus was on data-parallel programming, think about image processing whereby a large image is split in N chunks and each processor executes the same code on its chunk, providing a theoretical speed-up with a factor N. In reality, "grain size" and "communication latency" determine the unavoidable overhead. The idea was to use the principle of a spreadsheet. References from one cell to another cell can be seen as micro-messages. This worked well and we had the traditional Mandelbrot and equation of Laplace demos.
Around that time, INMOS put its transputer on the market. That was a great opportunity to put the ideas in practice. The development kit had 4 transputers and came with an occam compiler. I bought such an (expensive) kit and that was the start of a long story. First of all, although occam-1 was very simple and even had only 1 datatype (the byte), programming in occam had a steep learning curve to get working parallel programs. The compiler was unforgiving but if you got it compiled, the program would often run flawlessly. The main issue was not to have any deadlocks. After 1 month of error and trial I attended Professor Peter Welch's occam course and on the second day, the mental AHA switch happened. I watched my brain translating the simple exercise specification in "IF-THEN-ELSE" statements and realised that this was wrong. I also realised that this was the consequence being trained in programming using sequential languages whereby one tries to keep track of the whole state-space. The switch to concurrent thinking is to look for the actions in the specifications and then seeing how they are related. Actions become local processes and relationships become communication channels. Once, that mental switch is made, there is no way back. It is the natural way to analyse problems.
I then learned that this is the essence of Hoare's CSP. I summarise it here:
- No Shared State: Processes in CSP do not share memory; they communicate exclusively through explicit, synchronized channels. A process is sequential with descheduling points at channel communication. Each process executes in parallel with other processes.
- Synchronous Communication: A process sending a message (channel writer) must wait until another process receives the message (channel reader), providing built-in synchronization.
- Process Algebra: CSP provides mathematical methods to describe and verify the behavior of complex systems composed of simpler, smaller processes.
- Formalism: CSP uses mathematical modeling to prevent concurrency errors such as deadlocks, livelocks, and infinite overtaking.
Most importantly Hoare's was one of the pioneers who aimed for a Correctness by Construction: The goal of CSP is to enable the design of (concurrent) systems that are guaranteed to be correct through formal mathematical proof rather than just testing.
Two options remained: Spin and Leslie Lamport's TLA+. Professor Boute was our coach and TLA+ was selected. To make a long story short (the project took 3 years but was not a full-time activity), while there was a steep learning curve, we ended up doing things a bit differently. TLA+ was used to model and verify the architecture and the semantics, not the source code. That would have been a mistake as software sources evolve. The result was an RTOS kernel that implemented the concept of "Interacting Entities". The entities were mainly "Tasks" (processes in CSP) and the interactions the kernel services connecting the Tasks through intermediate" so-called "Hubs" (channels in CSP) but with much richer semantics, including asynchronous communication. The hubs and the packet switching also played a crucial role in the new architecture. The benefits were scalability, efficiency and maintainability. Unexpectidely, the code size shrank considerably, about a factor 10. The whole kernel now fitted in about 10 to 20 kb (this is very much processor dependent). The project was called "OpenComRTOS" and today lives on under the name VirtuosoNext. The current implementation supports fine-grain space partitioning and even allows to recover in micro-seconds from faults like overflow exceptions. The project was documented in a book (Formal Development of a network-Centric RTOS published by Springer).
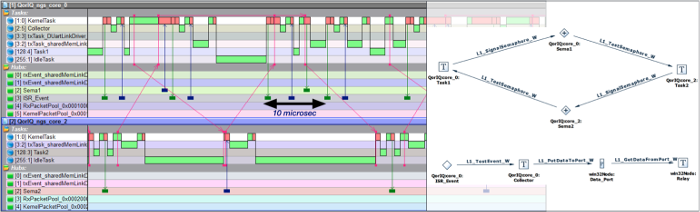
The project also opened a road towards trustworthy system design. It enhanced the capabiity to think in abstract terms about systems. In a small electric vehicle, the "Interacting Entities" concept was implemented in the drive-by-wire software of the 4 independent wheels. In the GoedelWorks project we sought to achieve "correct by construction" for systems using meta-modeling of the project entities but also of the development processes to be followed. A key element was the dependency graph that allowed to keep track of the impact of changes. Finally, the ARRL (Assured Reliability and Resilience Level) concept we introduced reflects that the ultimate goal of trustworthy systems engineering is not only to be fault-tolerant, secure or safe but to survive, being able to function as intended whatever happens to it. The safety concern was also the motivation to work with non-traditional cell chemistries at kurt.energy. The illegal state there is a battery fire that can have multiple root causes.
There are muliple lessons that can be drawn from this long road. First of all, formal approaches are a great way to rethink known solutions. Why, because they are a tool helping the mind to think in a more abstract way, away from implementation details. Known solutions often prevent progress as they bias how people look at things. It also helps to think out of the box, questioning established practices. Of course, formal techniques are harder to use (certainly in the beginning) and there is the scalability limit. The way to overcome that is to move to the meta-levels, abstracting away the details. Formalisation is the key. To illustrate this with a small example, in the RTOS a priority-sorted linked list is used everywhere to implement waiting semantics. The first TLA+ models (influenced by the existing source code) also modeled the linked list. The result was that the model checker would not handle the state space explosion. One needs a lot of memory for that. Then it dawned on us that for the semantics of the services, the priority didn't matter and we just replaced it with a Boolean. One bit replacing a complete function. Simple but Smart. A complex solution is often a problem not well understood. But making it simple can take a serious effort even if with hindsight it was trivial. With formalisation and meta-modeling, it easier to think about the core, not the details and better solutions are found.
There are many people who were involved in this roadmap. It were great times working with them as a team. I never programmed anything, even the C-language was never mastered. This was an advantage because it helped to think about behaviour, not about the implementation. The interested reader can browse www.altreonic.com and the internet for papers and presentations.
Eric Verhulst, 16th March 2026
New article in Science of Computer Programming magazine
Hubs for VirtuosoNext: Online Verification of Real-Time Coordinators
The paper is a collaborative effort of: Guillermina Cledoua (a), José Proença (b), Bernhard H.C. Sputh (c), Eric Verhulst (c)
(a)HASLab/INESC TEC, Universidade do Minho, Portugal, (b)CISTER, ISEP, Portugal, (c)Altreonic NV, Belgium
Extended version at Zenodo.org
Esevier paper at https://www.sciencedirect.com/
Abstract
VirtuosoNextTM is a distributed real-time operating system (RTOS) fea- turing a generic programming model dubbed Interacting Entities. This pa- per focuses on these interactions, implemented as so-called Hubs. Hubs act as synchronisation and communication mechanisms between the application tasks and implement the services provided by the kernel. While the kernel provides the most basic services, each carefully designed, tested and opti- mised, tasks are limited to this handful of basic hubs, leaving the development of more complex mechanisms up to application specific implementations.
This work presents a toolset that supports the building of new services compositionally, using notions borrowed from the Reo coordination language, on which the developer can delegate coordination-related duties. This toolset uses a formal compositional semantics for hubs that captures dataflow and time, formalising the behaviour of existing hubs, and allowing the defini- tion of new ones. Furthermore, it enables the analysis and verification of hubs under our automata interpretation, including time-sensitive behaviour via the Uppaal model checker, usable on http://arcatools.org/hubs. We illustrate the proposed tools and methods by verifying key properties on different interaction scenarios between tasks and a composed hub.
Altreonic and LikeAbird join forces
Date: 9th October 2017
Press Release:
Altreonic NV, provider of the unique fault tolerant VirtuosoNext RTOS environment, and
LikeAbird S.L.U., provider of the INAV-IG, the industrial grade Autopilot/Flight Control System Ecosystem for unmanned systems and drones
join forces in combining both technologies in an integrated platform.
LikeAbird is a R&D Think Tank company providing innovative systems, products and solutions in the field of the unmanned (air/land/sea) and robotic industry.
Fault tolerant VirtuosoNext RTOS for ARM Cortex-M microcontrollers
Altreonic has now ported the latest VirtuosoNext Designer to ARM Cortex M-series microcontrollers. The latest version fully exploits the Memory Protection support to provide fine-grain partitioning and allows fine-grain recovery from processor exceptions in a few microseconds at the Task level. This effectively provides fault tolerance for the applications without the system experiencing any significant delay and without having to apply costly hardware redundancy schemes. At the system level, the resilience level is greatly increased at virtually no cost. The economic advantages are significant.
Non-stop hard real-time processing with VirtuosoNext for safety

A fault-tolerant, fully distributed RTOS
Just when you thought there was nothing new anymore in the world of RTOS, the VirtuosoNext RTOS announces seamless fault-tolerance, a milestone for embedded safety and security.
Synopsis: As the world is moving towards "smarter" systems, often embedded, and our life and society is becoming dependent on their uninterrupted operation, fault-tolerance is becoming a prime requirement. Just think about autonomous driving. Will it safely bring you home all the time? In case of a system fault, the reaction time is less than 100 milliseconds. No time for a reboot.
A consequence of the fine-grain space partitioning support in VirtuosoNext is the capability to recover from runtime faults within a few microseconds. The combination of fine-grain concurrency and this fast recovery effectively provides support for non-stop hard real-time processing even when faults occur without a complex and costly system design. VirtuosoNext non-stop capability means that fault-tolerance comes in reach in a cost-efficient manner, as well as in terms of development effort as in terms of compute resources.
New booklet on real-time programming of multicore processors
Altreonic has released an updated version of its "QoS and real-time requirements for embedded many- and multicore systems" booklet. A major chapter was added covering the fine-grain partitioning support of VirtuosoNext on several target processors (Texas Instruments M3, A9, C6678 and Freescale 2080). The paper clearly shows that partitioning support for safety and security can be implemented with almost no penalties for the real-time behaviour. In addition, the code size remains very modest (ranging from less than 10 kbytes to 38 kbytes depending on the target). Download the attached publication for more details.
VirtuosoNext RTOS unleashes the power of Sundance’s OpenVPX DSP board
Together they create a powerful and ultra-high bandwidth processing platform ideally suited for computation and bandwidth-intensive high-reliability and safety-critical applications
Chesham, UK – 21st February 2017. Sundance Multiprocessor Technology Ltd., an established supplier and manufacturer of high performance embedded solutions, has collaborated with Altreonic to port its multicore VirtuosoNextTM Designer embedded RTOS to Sundance’s VF360 3U OpenVPX single board computer (SBC), that integrates a Texas Instruments C6678 Keystone multicore DSP alongside an Altera Stratix® V FPGA.
Read more in the attached press release.
Altreonic selected in EuroCPS open call with VirtuosoNext
Altreonic has been selected in the EuroCPS project to port a Flight Management test application with VirtuosoNext on an avionics platform of Thales. EuroCPS is an European funded project focusing on advanced computing and cyber-physical systems. It gathers several design centers in order to boost and initiate synergies between innovative companies, major CPS-platforms and CPS-competency providers. The specific project with Altreonic is labeled NoFiST (Novel Fine Grain Space and Time Partitioning for a Mixed Criticality Platform) and is a cooperation with Thales TRT. Hereby the abstract:
VirtuosoNext™ Designer ignites TI’s C6678 RoC on Parsec VF360
Altreonic has now ported VirtuosoNext™ Designer to the Texas Instruments’ 8-core C6678 DSP of Sundance’ Parsec VF360 VPX board. The board has 8 floating point DSPs and an Altera Stratix-V on board and is a real single chip signal processing embedded super computer. Running at 1.25 GHz, the eight cores deliver together up to 224 GFlops with a peak bandwidth of 16 Gbytes/s.
Altreonic releases VirtuosoNext v.1.1
Altreonic is proud to announce the release of the version 1.1 of VirtuosoNext™, its high level yet very performant design and programming solution for trustworthy systems development. VirtuosoNext is derived from the formally developed network-centric and distributed OpenComRTOS who’s functionality is inherited.
VirtuosoNext adds the capability to apply fine-grain time and space partitioning when the hardware supports it. VirtuosoNext provides safety measures to trap runtime errors without the system coming to a halt. The approach separates the code in a trusted zone (managed by the VirtuosoNext kernel) and an untrusted zone (executing application tasks). Contrary to traditional hypervisor approaches, the code size and performance penalty is minimal safeguarding the real-time response of a traditionally unprotected RTOS as standard priority based preemptive scheduling is maintained.
VirtuosoNext (protected mode) was initially disclosed in April 2015 This new release has also restructured the code resulting in even lower code sizes. On the ARM-M3, the VirtuosoNext kernel measures between 8 to 11.5 Kbytes. On the ARM A9, the kernel measures between 15 to 22 Kbytes.
Supported processors are ARM M3/M4/R4/R5 and the A7/A9/A15 processor family. The user has the option to enable the protection on specified processing nodes in his distributed or manycore target system. VirtuosoNext 1.1 will hence on make the previous and stable OpenComRTOS v.1.6 superseded as its functionality is integrated. The new services and improvements added with VirtuosoNext v.1.1 can be consulted in the attached files.
Share |