You are hereNon-stop hard real-time processing with VirtuosoNext for safety
Non-stop hard real-time processing with VirtuosoNext for safety

A fault-tolerant, fully distributed RTOS
Just when you thought there was nothing new anymore in the world of RTOS, the VirtuosoNext RTOS announces seamless fault-tolerance, a milestone for embedded safety and security.
Synopsis: As the world is moving towards "smarter" systems, often embedded, and our life and society is becoming dependent on their uninterrupted operation, fault-tolerance is becoming a prime requirement. Just think about autonomous driving. Will it safely bring you home all the time? In case of a system fault, the reaction time is less than 100 milliseconds. No time for a reboot.
A consequence of the fine-grain space partitioning support in VirtuosoNext is the capability to recover from runtime faults within a few microseconds. The combination of fine-grain concurrency and this fast recovery effectively provides support for non-stop hard real-time processing even when faults occur without a complex and costly system design. VirtuosoNext non-stop capability means that fault-tolerance comes in reach in a cost-efficient manner, as well as in terms of development effort as in terms of compute resources.
Why do systems fail?
From time to time, the public is made aware of catastrophic failures induced by software errors. Such failures happen all the time but do not always make it to the news. A failing car is considered an annoyance, a failing mission to Mars or an airplane crashing is a costly disaster. It is no wonder that in safety critical sectors much attention is given to the engineering process and in particular to the correctness of the software. Formal methods, rigorous processes, and external reviews by experts all aim at bringing the probability of failure to the lowest acceptable level. Still, systems can fail spectacularly. Think about several missions to Mars, the first Ariane-5 rocket launch, the failing Patriots during the first Gulf war, etc. Sometime the failure is not even induced by the software or the processors but by a failing power supply as recently happened at British Airways.
Why do such systems still fail? A first obvious reason is human error. Even when using formal techniques, it is very difficult to obtain a complete set of specifications that take into account all real-world circumstances. Formal models might be proven correct, but remain incomplete models of a much more complex world. Or the software engineer made a subtle mistake that no toolchain can catch or worse that will never be tested for because the mistake is unknown. And last but not least, software is an imperfect execution on an imperfect piece of hardware. In a digital world, software datatypes have a limited precision even if the real world variables are continuous and can have any value. In addition, the bits that represent that data in the processor can become corrupted, for example because a cosmic ray induced extra electric charges in the circuit, or because a power glitch caused a bit to change its value. As chip features are continuously shrinking and chips operate at lower voltages, this becomes more probable. Moreover, embedded systems work with real-world sampled data. The precision and range of the sensor introduces numeral imprecision and noise that when not properly taken into account can result in large deviations when used in long calculations. Any of these examples, and there are many more, will most likely result in a failure of the software and ultimately in a failing of the system.
A smart world needs to be fault-tolerant
 Computers have taken over the world, but they went into hiding as well and we call them embedded. Many of our systems (cars, energy networks, telecommunication systems, etc.) would not even be able to offer the service they provide without their "embedded" computers. Today, these systems are becoming "smart" and adaptive. They can do this by constantly monitoring our environment and by interpreting what their sensors measure. An example of an emerging market are autonomous systems, e.g. self-driving cars and drones. Such systems have control loops measured in milliseconds. If they fail, the impact can be catastrophic because of avalanche effects. To reduce these risks to a minimum, they must be able to continue to operate even when faults occur. We call this an ARRL-3 system, or with extra hardware redundancy an ARRL-4 or -5 system (see http://www.altreonic.com/content/arrl-novel-criterion-trustworthy-safety-critical-systems). The novel non-stop capability of the VirtuosoNext RTOS provides higher safety at a much lower development and implementation cost. Esssentially, the non-stop capability offers ARRL-4 in an ARRL-3 package (when using the right hardware such as the presence of an MPU or MMU and error correcting logic for e.g. program memory).
Computers have taken over the world, but they went into hiding as well and we call them embedded. Many of our systems (cars, energy networks, telecommunication systems, etc.) would not even be able to offer the service they provide without their "embedded" computers. Today, these systems are becoming "smart" and adaptive. They can do this by constantly monitoring our environment and by interpreting what their sensors measure. An example of an emerging market are autonomous systems, e.g. self-driving cars and drones. Such systems have control loops measured in milliseconds. If they fail, the impact can be catastrophic because of avalanche effects. To reduce these risks to a minimum, they must be able to continue to operate even when faults occur. We call this an ARRL-3 system, or with extra hardware redundancy an ARRL-4 or -5 system (see http://www.altreonic.com/content/arrl-novel-criterion-trustworthy-safety-critical-systems). The novel non-stop capability of the VirtuosoNext RTOS provides higher safety at a much lower development and implementation cost. Esssentially, the non-stop capability offers ARRL-4 in an ARRL-3 package (when using the right hardware such as the presence of an MPU or MMU and error correcting logic for e.g. program memory).
Current remedies
So, what do engineers do to deal with these unlikely but inevitable failures? The most common approach is known by all of us when our PC presents us with a frozen screen: switch off the power and reboot. As anyone knows, this is brutally simple, but it can take a serious amount of time from tens of seconds to minutes. In complex systems like airplanes it can take a lot more time as the rebooting results in mandatory system checks. Therefore, the reboot option is hardly a valid one when dealing with safety critical real-time systems.
Another option is to use partitioning. Derived from the server world, partitioning is based on very trustworthy software that runs on top of the hardware, typically called a hypervisor. The latter will assign applications to specific memory regions and typically share the time between time partitions taking tens of milliseconds. If a failure occurs, the whole partition is re-initialised and the application is rebooted, leaving the rest of the system intact. While this avoids the complete reboot of the whole system, the impact on the failing application can still be substantial as outlined in the previous paragraph. It is not compatible with hard real-time when safety and security risks are present.
VirtuosoNext changes this in a disruptive and very convenient way. It allows applications to recover in a few microseconds without disrupting the continued execution of the application. VirtuosoNext Designer uses a combination of code generators and a formally developed small but distributed real-time kernel. Partitioning starts when the application is written. An application is very naturally written as a number of tasks that synchronise and communicate by using so-called hub entities. In practice these hub entities will present themselves as traditional RTOS services like events, semaphores, resource locks, mailboxes, etc. From the top level application model description, code generators generate the data structures, the initialisation code and static program images that can't be modified at runtime as they reside in read-only memory. A key element are the semantics of these hub services. The services pass their data by copying and with strict hand shaking. The data is passed on to the kernel task which in turn then delivers the data to the corresponding task. While it is possible to pass address pointers, this is only allowed for so-called trusted code, for example the kernel task and driver tasks.
First line of defense: decoupling
The first line of defense is that the underlying implementation fully decouples and strictly separates the application tasks from each other. If the program is correctly developed (hence not using shared memory unless under strictly controlled circumstances), no task will access the memory of another task. As the scheduling is not time based but event and priority based, small timing differences have no impact on the correct operation of the program. This is further reinforced by the use of an underlying packet-switching mechanism that also support transparent programming across multiple processors, be it that the CPUs reside on the same chip (many/multicore processors) or across a network.
Second line of defense: fine grain partitioning at task level
The second line of defense is that VirtuosoNext Designer will allocate each task his own private memory space, fully protected by the memory protection logic of the processors. Also the code itself is protected and "read-only", avoiding that it can be unwillingly modified. No task can read or write in the memory of another task, even as a result of a programming error or a fault in the hardware. If such a fault would happen then the task will fail, but the rest of the system will continue to execute, unless another task was dependent on the execution of the failing task. In this case, the system will not crash but will stall, waiting for its data to arrive (over one of the Hub entities). In many cases even this will not happen as using a hub service like a blackboard, the task can just read the latest data from that hub and continue. Note also that for security risks, this effectively limits the risks as well.
Third line of defense: recovery in microseconds
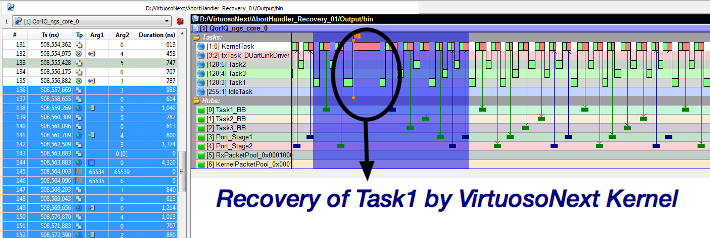
Hence, there is a third line of defense. If such an erroneous, unlikely but not improbable event happens, the kernel will intercept it and immediately install the task specific abort handler. In the abort handler, the programmer can clean up the state of the failing tasks, e.g. by releasing all resources, if any. Or he can execute a copy of the task's function which allows to cope with bit errors in program memory. This is a form of temporal redundancy using a spatial duplicate. A typical abort handler is very short and upon termination, the kernel will simple re-initialise the failing task so that the application can continue with no noticeable delay. The recovery delay is measured in microseconds, 2.3 microseconds to be precise on a Freescale QorIQ T2080/1 processor running at 1.8 GHz with all tasks protected in memory.
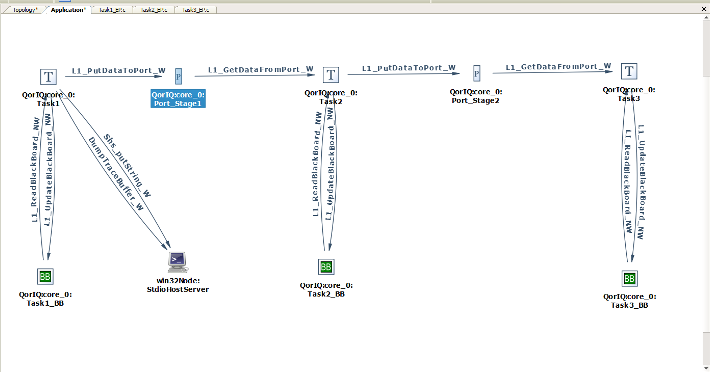
Below, the application diagram in VirtuosoNext' Visual Designer shows a number of pipelined tasks using Port hubs to exchange data and BlackBoard hubs to safeguard a consistent state of the data should an exception happen. In Task1, en exception (memory violation) is deliberately inserted. The trace shows the execution of the recovery (see the little flag). As the reader will notice, the effect on the execution of the task is barely noticeable. In this case it introduces an extra delay of about 4.3 microseconds (including the tracing adding about 2 microseconds).
 Fourth line of defense: redundancy
Fourth line of defense: redundancy
Last but not least, VirtuosoNext provides transparent programming of multiple cores, be it on the same chip (multi/manycores) or distributed (using a interprocessor network). This means that it becomes relatively easy to run multiple copies of the same application on all cores. As these cores are not likely to have same fault simultaneously, one can insert voting blocks that compare the intermediate outputs, so that even when a task fails, the application can continue. This even works when applying diversity (different code running on different processor types) to reduce common mode failures. As the recovery is in microseconds, the system can continue uninterrupted.
Benefits for embedded security
While above defense mechanisms are often associated with safety-criticality, they also offer a good defense against security related issues. After all, these are sub cases of safety related faults, being maliciously injected. First of all, the set-up makes it very hard if not impossible to insert alien (malicious) code as the image is static and read-only (we assume here that the system initialisation is a secure process step). Hence, an attack can only come from injecting faulty data. As most embedded systems have unsecured openings towards the public world, this is not impossible. But again, the packet switching helps. Packets can be encrypted, authentification can be added and moreover, whenever a wrongly formatted packet comes in, it can be rejected and if needed the driver can be disabled and restarted. The physical isolation offered by VirtuosoNext can enforce that such erroneous data never reaches the really critical parts of the application.
Non-stop hard real-time in the presence of faults
What this means is that in most cases, applications can continue non-stop and remain hard real-time even when faults occur. An extra delay of a few microseconds can be fully tolerated if the systems' update rate is measured in milliseconds. Note that in combination with the transparent support for running a task on any processor, this approach makes it also very easy to implement redundancy. As the hardware is often very reliable, only common mode failures will bring the system to a halt. With the non-stop capability of VirtuosoNext, the need for extra redundant hardware and the probability of a fatal error is greatly reduced.
Note that with VirtuosoNext, the fine grain space partitioning support entails very little extra overhead. Interrupt latencies are still measured in nanoseconds and microseconds. The system timer can be as short as 10 microseconds. Codesize is less than 38 KBytes for a minimal application (including the compiler runtime library). For details see http://www.altreonic.com/content/virtuosonext%E2%84%A2-designer-freescale-qoriq-t20801 and Goedel Series booklet on real-time
The non-stop capability is also made available for ARM Mx/Rx and Axx, LEON-3/4 and selected Intel processors. Available under an Open Technology License.
Questions? Contact us via email.
- Printer-friendly version
- Login to post comments